

From Probabilistic Foundations to the Naive Bayes Classifier (ML for Quants: Part 7)
Introduction to Supervised Learning in Finance
In last module of this curriculum, we explored unsupervised machine learning, where the goal was to find hidden structures within unlabeled data. We now transition again into Supervised Machine Learning. In this paradigm, we deal with labeled data: we have input variables (predictors/features) and a known target variable. Our objective is to build a model that maps the inputs to the target with high accuracy.
This article focuses on one of the most fundamental probabilistic approaches to classification: Bayesian Statistics. Specifically, we will examine how Bayes’ Theorem can be applied to predict binary financial outcomes such as whether a stock should be a “Buy” or “Hold,” or whether a loan applicant will “Default” or “Repay.” We will traverse the theoretical derivation of the theorem, the assumptions behind the “Naive” Bayes classifier, and finally, a robust implementation using Python.
Section 1: The Bayesian Framework
To understand Bayesian statistics, we must first ground ourselves in the concept of conditional probability. In classical frequentist statistics, we often view probability as the long-run frequency of events. However, the Bayesian view interprets probability as a measure of belief or certainty about an event, which is updated as more evidence becomes available.
1.1 Collective Exhaustive Events
In binary classification problems, we often deal with a collectively exhaustive set of events. This means the set of all possible outcomes covers 100% of the possibilities.
If we define an event A (e.g., a company defaults), and its complement \(\overline{A}\) (the company does not default), then:
$$P(A) + P(\overline{A}) = 1$$
Therefore, knowing the probability of one outcome immediately gives us the other:
$$P(A) = 1 – P(\overline{A})$$
1.2 Conditional Probability and Derivation
Bayesian analysis relies heavily on conditional probability; the probability of an event occurring given that another event has already occurred.
Let:
- Y: The target variable (Class), e.g., Default (1) or No Default (0).
- X: The predictor variable (Feature), e.g., “Employed for < 3 years”.
We denote the probability of Y occurring given X as P(Y|X).
From basic probability theory, the joint probability of both events happening $P(Y cap X)$ can be expressed in two ways:
- \(P(Y cap X) = P(Y|X) \cdot P(X)\)
- \(P(Y cap X) = P(X|Y) \cdot P(Y)\)
Since both equations equal $P(Y cap X)$, we can set them equal to each other:
$$P(Y|X) \cdot P(X) = P(X|Y) \cdot P(Y)$$
Rearranging this formula to solve for our target prediction P(Y|X), we arrive at Bayes’ Theorem:
$$P(Y|X) = \frac{P(X|Y) \cdot P(Y)}{P(X)}$$
1.3 The Components of Bayes’ Theorem
It is crucial for a practitioner to understand the terminology of each component in this equation:
- The Prior, P(Y): This is our initial belief about the probability of the class occurring before seeing any specific data (features). For example, if 5% of all companies default, our prior is 0.05.
- The Likelihood, P(X|Y): This asks: “If the company were indeed going to default (Y), what is the probability they would have this specific feature (X)?” This is calculated from historical data.
- The Evidence (or Marginal), P(X): This is the total probability of the feature occurring across all classes. It acts as a normalizing constant to ensure the resulting probability lies between 0 and 1.
- The Posterior, P(Y|X): This is the final result—our updated belief about the class probability after observing the feature.
Section 2: The “Naive” Assumption
In real-world financial problems, we rarely rely on a single predictor. We usually have a vector of features \(X = [x_1, x_2, …, x_n]\).
Ideally, we would calculate the posterior based on the joint distribution of all features:
$$P(Y|x_1, x_2, …, x_n) = \frac{P(x_1, x_2, …, x_n | Y) \cdot P(Y)}{P(x_1, x_2, …, x_n)}$$
2.1 The Curse of Dimensionality
Calculating the true joint likelihood \(P(x_1, x_2, …, x_n | Y)\) is computationally expensive and requires massive amounts of data. As the number of features grows, the number of possible combinations grows exponentially.
2.2 The Independence Assumption
To solve this, we make a Naive assumption: We assume that all predictor variables are independent of one another, conditional on the class Y.
Mathematically, this simplifies the likelihood calculation from a complex joint distribution to a simple product of individual probabilities:
$$P(x_1, x_2, …, x_n | Y) \approx P(x_1|Y) \cdot P(x_2|Y) \cdot … \cdot P(x_n|Y)$$
This transforms our classifier equation into:
$$P(Y|X) \propto P(Y) \prod_{i=1}^{n} P(x_i|Y)$$
While the independence assumption is rarely 100% true in financial data (e.g., a company’s “Debt” and “Interest Expense” are correlated), the Naive Bayes classifier often performs surprisingly well in practice because the direction of the correlation often points to the correct class, even if the exact probability estimate is slightly biased.
Section 3: Handling Continuous Variables (Gaussian Naive Bayes)
The examples above assume categorical data (e.g., Sector = Mining). However, financial data is often continuous (e.g., P/E Ratio, Return on Equity).
To apply Naive Bayes to continuous data, we must model the likelihood \(P(x_i|Y)\) using a probability distribution. The most common choice is the Normal (Gaussian) Distribution.
We assume that for each class Y, the feature \(x_i\) is distributed normally with a mean \(mu_y\) and variance \(sigma^2_y\):
$$P(x_i|Y) = \frac{1}{\sqrt{2\pi\sigma_y^2}} e^{ -\frac{(x_i – \mu_y)^2}{2\sigma_y^2} }$$
When training the model, we simply calculate the mean and variance of each feature for the “Default” class and the “No Default” class separately. These statistics become our model parameters.
Section 4: Practical Implementation in Python
We will now implement a Gaussian Naive Bayes classifier using Python and scikit-learn. We will simulate a scenario where we predict whether a stock provides a positive return (Class 1) or negative return (Class 0) based on two factors.
4.1 Step 1: Library Import and Data Generation
First, we import the necessary libraries. We will use sklearn.naive_bayes.GaussianNB for the model and generate synthetic data to demonstrate the mechanics clearly.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report
# Generating synthetic financial data
# Feature 1: Momentum (Continuous)
# Feature 2: Value Score (Continuous)
np.random.seed(42)
n_samples = 1000
# Generating "Good" stocks (Class 1)
good_momentum = np.random.normal(0.5, 1.0, 500)
good_value = np.random.normal(0.5, 1.0, 500)
labels_good = np.ones(500)
# Generating "Bad" stocks (Class 0)
bad_momentum = np.random.normal(-0.5, 1.0, 500)
bad_value = np.random.normal(-0.5, 1.0, 500)
labels_bad = np.zeros(500)
# Combining data
X = np.column_stack((np.concatenate([good_momentum, bad_momentum]),
np.concatenate([good_value, bad_value])))
y = np.concatenate([labels_good, labels_bad])
print(f"Data Shape: {X.shape}")
4.2 Step 2: Splitting Data
We must separate our data into training and testing sets to evaluate performance on unseen data.
X_train,X_test,y_train,y_test =train_test_split(X,y,test_size=0.25,random_state=42)
4.3 Step 3: Training the Model
We instantiate the GaussianNB classifier. When we call .fit(), the algorithm calculates the prior probabilities $P(Y)$ and the likelihood parameters ($mu$ and $sigma$) for each feature for each class.
# Initialize the Gaussian Naive Bayes classifier
gnb = GaussianNB()
# Train the model
gnb.fit(X_train, y_train)
# Output the learned priors (Class probability)
print(f"Class Priors (Bad, Good): {gnb.class_prior_}")
print(f"Feature Means (Bad Stocks): {gnb.theta_[0]}")
print(f"Feature Means (Good Stocks): {gnb.theta_[1]}")
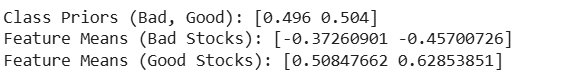
4.4 Step 4: Making Predictions
The model calculates the posterior probability for the test set and assigns the class with the highest probability.
# Make predictions
y_pred = gnb.predict(X_test)
# Evaluation
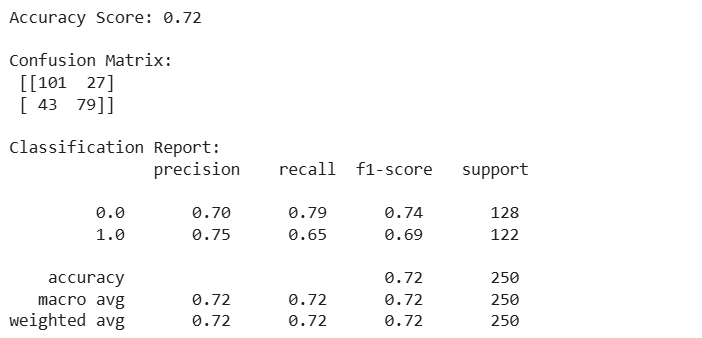
print("Accuracy Score:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
Conclusion
The Naive Bayes classifier provides a probabilistic approach to machine learning. By leveraging Bayes’ Theorem, it updates the prior belief of a financial outcome using the evidence provided by new data. Despite the “naive” assumption of feature independence, the Gaussian Naive Bayes model is a powerful baseline tool for continuous financial data, offering speed, interpretability, and solid performance, particularly when data is limited.
In the next part of this series, we will move away from strict probabilistic independence and explore Tree-Based Models, which can capture complex, non-linear interactions between variables.